|
- 小学二年级
- 5053044
- 33
- 0
- 54 朵
- 110 个
- 221 个
- 1160
- 2018-02-17
|
1#
t
T
发表于 2021-11-18 23:20
|
|只看楼主

大家好,我是大猪蹄子,闲着无聊,发个按键爬取网络上免费小说的教程,没用正则,变量名字也简洁易懂,方便新手学习,按键能做的事情还是很多的,希望按键越来越好,bug越来越少.话不多说,源码奉上.==============================源码===================================== - 网页 = "https://www.xbiquge.la" : 完整网页 = 网页 & "/32/32522/"
- 原网页源码 = 网页_获取网页源文件(完整网页)
- 保存位置 = "C:\Users\Administrator\Desktop\小说爬取\"
- If Plugin.File.IsFileExist(保存位置) = false Then
- Call Plugin.File.CreateFolder(保存位置)
- TracePrint "创建小说文件夹"
- End If
- //Plugin.File.WriteFileEx "C:\Users\Administrator\Desktop\百度.txt", 原网页源码
- 开始位置 = 1
- If 原网页源码 <> "" Then
- Do
- 内容 = 取中间文本(原网页源码, "<dd><a href='", "' >第", 开始位置,1)
- 内容 = Replace(内容, "<dd><a href='", "")
- If 内容 <> "" Then
- // TracePrint "网址" & 网页 & 内容
- 获取章节正文 网页 & 内容
- Else
- TracePrint "内容为空,停止" & time : Exit Do
- End If
- Loop
- End If
- Function 获取章节正文(网址)
- For 20
- 没处理网页源码 = 网页_获取网页源文件(网址)
- //Plugin.File.WriteFileEx "C:\Users\Administrator\Desktop\百度2.txt", 没处理网页源码
- If 没处理网页源码 <> "" Then
- 章节 = 取中间文本(没处理网页源码, " <h1>全部章节", "</h1>", 1,0)
- 章节 = Replace(章节, "<h1>", "") : 章节 = Replace(章节, "全部章节", "")
- 文章内容 = 取中间文本(没处理网页源码, " ", "<p><a href=", 1,0)
- 文章内容 = Replace(文章内容, "<br /> ", "") '删除正文中的多余符号
- 文章内容 = Replace(文章内容, "<br />", "") '删除正文中的多余符号
- 文章内容 = Replace(文章内容, " ", "") '删除正文中的多余符号
- If 文章内容 <> "" Then
- Plugin.File.WriteFileEx 保存位置 & 章节 & ".txt", 章节
- Plugin.File.WriteFileEx 保存位置 & 章节 & ".txt", 文章内容
- TracePrint "爬取章节 - " & 章节 : Exit Function
- End If
- End If
- Next
- TracePrint "内容为空,爬取结束 " & 网址 : ExitScript
- End Function
- Function 取中间文本(原文本, 左边文本, 右边文本, 左边位置,赋值1)
- Dim 返回长度, 开始, 结束
- 取中间文本=""
- 开始 = InStr(左边位置, 原文本, 左边文本, 1)
- If 开始 > 0 Then
- 结束 = InStr(开始, 原文本, 右边文本, 1)
- If 结束 > 开始 Then
- 返回长度 = 结束 - 开始
- 取中间文本 = mid(原文本, 开始, 返回长度)
- If 赋值1 = 1 Then 开始位置 = 结束
- Else
- TracePrint "取中间文本错误,开始" & 开始 & "结束" & 结束
- End If
- End If
- End Function
- Function 网页_获取网页源文件(网址)
- '此函数可以模拟成真实访问
- Set xmlHttp = CreateObject("Microsoft.XMLHTTP")
- xmlHttp.Open "Get", 网址, False
- xmlHttp.Send
- 网页_获取网页源文件 = xmlHttp.ResponseText
- Set xmlHttp = Nothing
- End Function
===================效果图========================   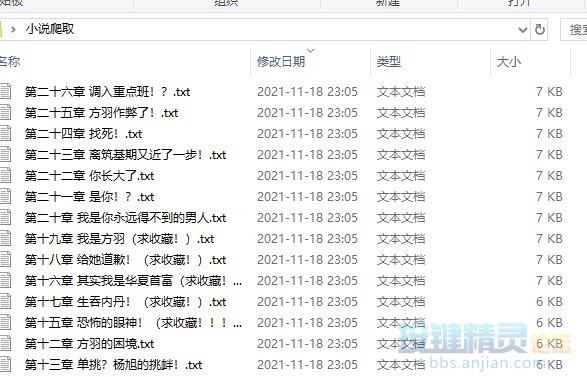
点评
果壳王子
恭喜获得小编勋章、教程达人勋章
发表于 2021/11/19 10:25:59
|




 闽公网安备 35010002000112号
闽公网安备 35010002000112号