实现效果:[判断攻击力总和]
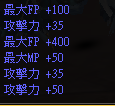 思路1:[全区域ocr识别]
思路1:[全区域ocr识别]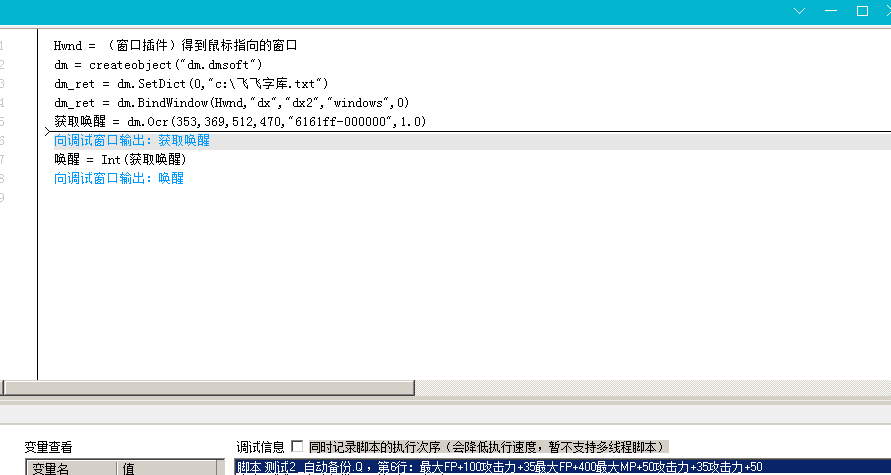
识别结果:"最大FP+100攻击力+35最大FP+400最大MP+50攻击力+35攻击力+50"
结论:分割困难
思路2:[多区域ocr识别]
 思路3:[因为装不固定所以固定区域识别不行,识别装备属性框特征在偏移计算多区域识别的区域过于繁琐]
思路3:[因为装不固定所以固定区域识别不行,识别装备属性框特征在偏移计算多区域识别的区域过于繁琐]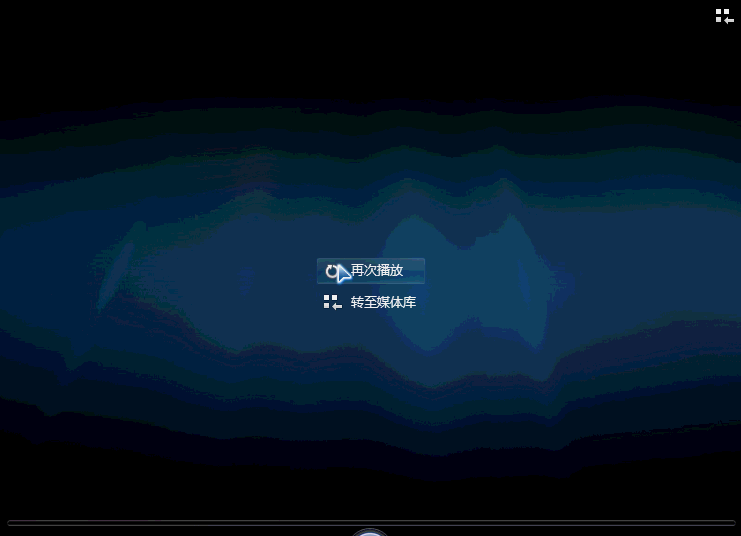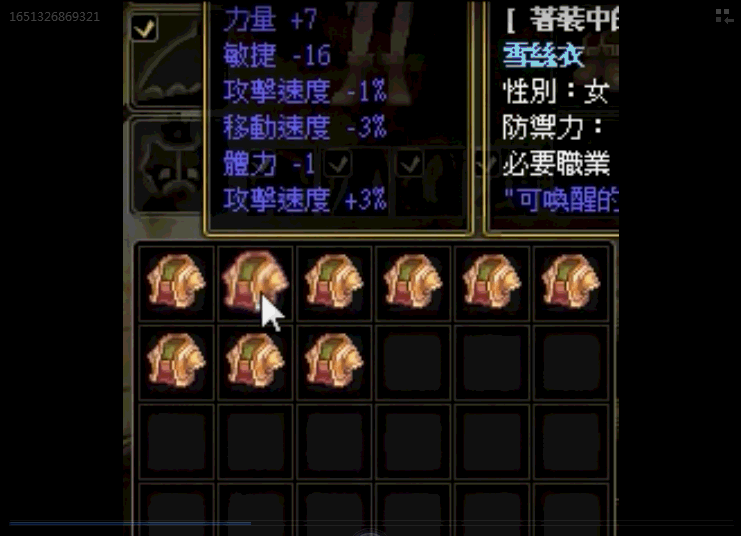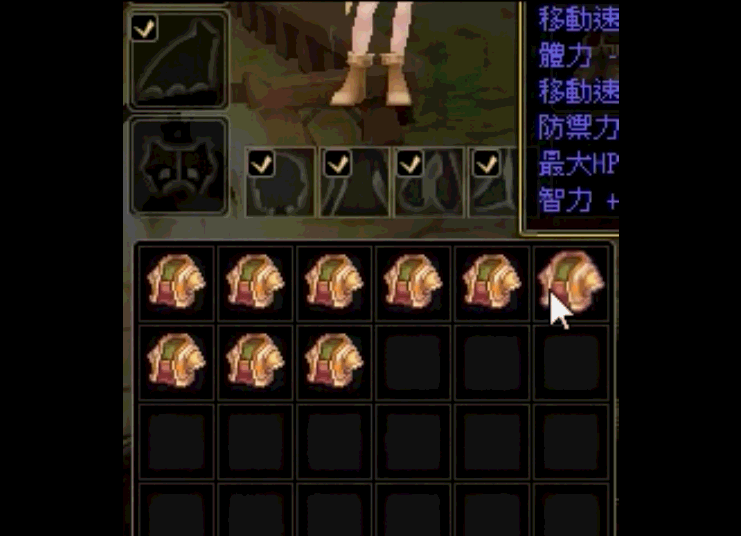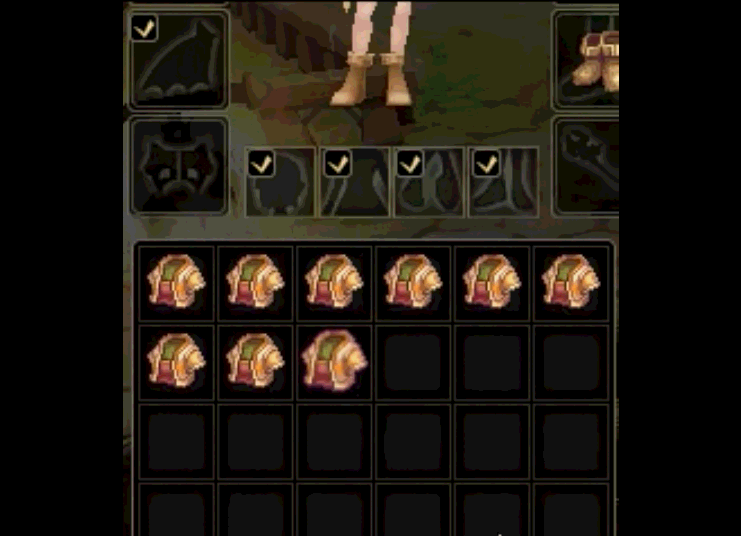

- var = "最大FP+100攻击力+35最大FP+400最大MP+50攻击力+35攻击力+50"
- For i = 1 To len(var)
- If IsNumeric(mid(var, i, 1)) = True and i < len(var) Then
- If IsNumeric(mid(var, i + 1, 1)) = False Then
- 重组var = 重组var & mid(var, i, 1) & "|"
- Else
- 重组var=重组var& mid(var, i, 1)
- End If
- Else
- 重组var=重组var& mid(var, i, 1)
- End If
- Next
- TracePrint 重组var
- 分割 = split(重组var, "|")
- For i = 0 To UBound(分割)
- TracePrint 分割(i)
- Next
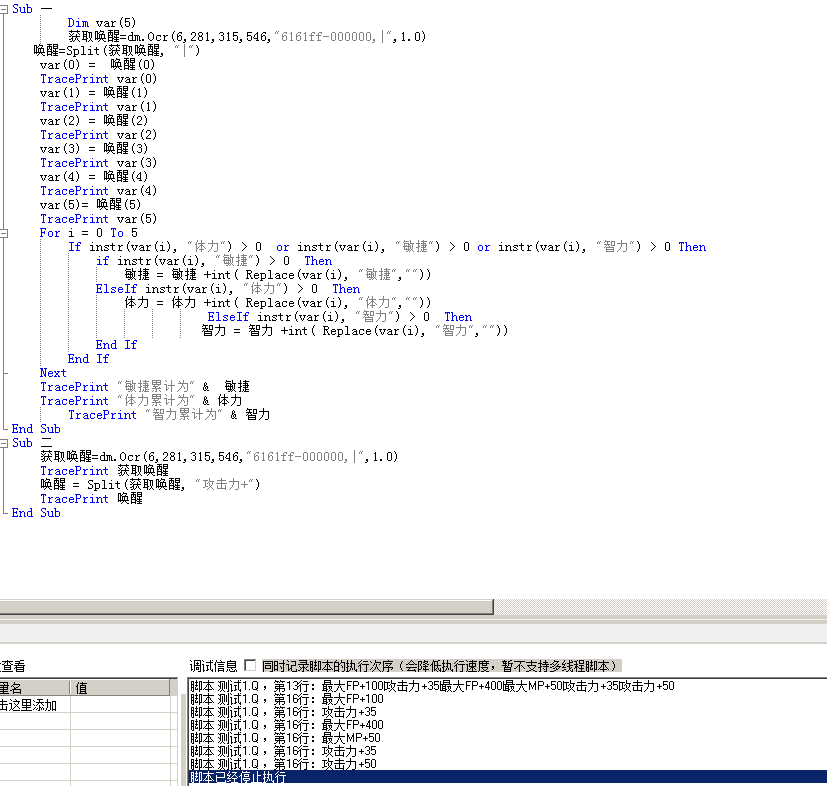
- //识别后,每行字符串用指定字符分割
- 比如用"|"字符分割
- s = dm.Ocr(0,0,2000,2000,"9f2e3f-000000,|",1.0)
- MessageBox s
识别1和11不混淆
set dm = createobject("dm.dmsoft")
dm_ret = dm.SetPath("C:\大漠")
dm.SetDict 1, "大漠字库.txt"'将字库排为1
dm_ret = dm.UseDict(1)'调用排为1的字库
hwnd = dm.GetMousePointWindow()
dm_ret = dm.BindWindow(hwnd,"normal","normal","normal",1)
Delay 1000
s = dm.GetWords(0,0,2000,2000,"6C6A97-6b6668",1.0)
count = dm.GetWordResultCount(s)
index = 0
Do While index < count
dm_ret = dm.GetWordResultPos(s,index,intX,intY)
word = dm.GetWordResultStr(s,index)
TracePrint intX & "," & intY & "," & word
If word = 1 Then
dm.MoveTo intX, intY
Delay 1000
End If
index = index + 1
Loop
Sub OnScriptExit()
dm.UnBindWindow
End Sub





 闽公网安备 35010002000112号
闽公网安备 35010002000112号